




Dla NeuroSYS zrealizowaliśmy projekt migracji środowiska deweloperskiego, bazującego na mikroserwisach, do chmury AWS, w oparciu o platformę Kubernetes. Ponieważ Klient nie miał wcześniej zasobów związanych z działaniem aplikacji w AWS oraz kontenerami, zakres naszej współpracy obejmował również szkolenia, mające na celu wdrożenie pracowników NeuroSYS, a cały projekt oparty był o inżynierię oprogramowania CI/CD.
NeuroSYS to software house, który zajmuje się na tworzeniem dedykowanych rozwiązań IT, w szczególności w obszarze aplikacji internetowych, mobilnych oraz sztucznej inteligencji. Jednym z produktów firmy jest nsFlow - zintegrowana platforma, która umożliwia projektowanie i uruchamianie aplikacji AR w celu optymalizacji procesów biznesowych.
Naszą współpracę z firmą NeuroSYS rozpoczęliśmy od przeprowadzenia wywiadu, w ramach którego ustaliliśmy dokładne oczekiwania biznesowe i technologiczne Klienta. Najważniejsze z nich to możliwość elastycznego i dynamicznego dopasowywania rozmiarów infrastruktury w zależności od potrzeb, możliwość błyskawicznego wdrażania wielu środowisk oraz infrastruktura stworzona zgodne z metodologią DevOps i podejściem IaC, które zminimalizują wysiłek związany z odtwarzaniem i kopiowaniem środowiska (dev/test/stage oraz disaster recovery). Ponadto ważnym aspektem dla Klienta było zoptymalizowanie kosztów i utrzymanie dobrych praktyk związanych z zasadami bezpieczeństwa systemów chmurowych.
Platforma chmurowa i konta AWS
Całość infrastruktury zdefiniowaliśmy i zrealizowaliśmy przy pomocy narzędzia Terraform. Kod realizacji platformy utrzymywany jest w ramach serwerów Klienta. Po stronie Klienta pozostało również przygotowanie dedykowanego repozytorium na platformie GitLab oraz przekazanie Hostersom uprawnień do użytkowania i modyfikacji kodu podczas wykonywania prac. Pełen projekt infrastruktury chmurowej został przedstawiony na poniższym rysunku.
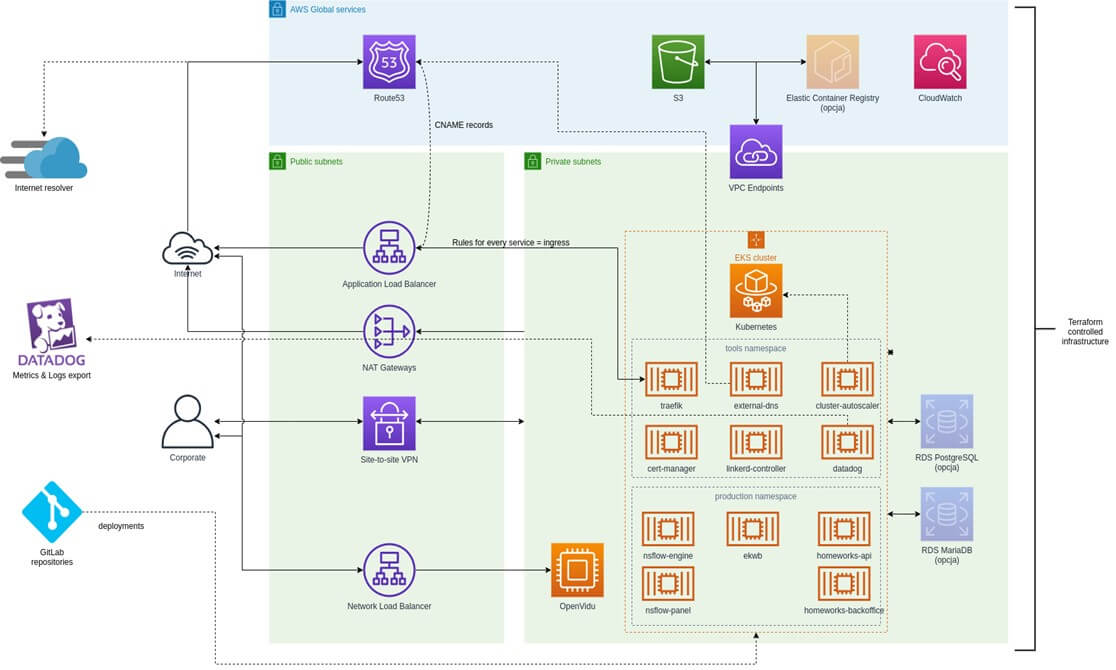
Konto AWS zostało przygotowane przez Klienta. Wspólnie określiliśmy użycie odpowiednich ról i łańcuchów zaufania do odpowiednich kont organizacji. Komponentami, których konfiguracja pozostała po stronie Hostersów, były konta serwisowe wykorzystywane przez automatykę, wdrożenie zachowywania informacji o dostępnie i wykorzystaniu AWS API (CloudTrail) oraz elementy wykorzystywane przez IaC (bucket AWS S3, tabela Dynamo DB) w celu zachowania i ochrony infrastruktury.
Wirtualna sieć VPC
Ze względu na pełną separację środowiska produkcyjnego, utworzyliśmy niezależne od siebie sieci VPC przeznaczone dla komponentów aplikacji i usług, które wykorzystują. Wirtualne sieci rozszerzone są o obszar prywatny (podsieci prywatne), co oznacza, że nie mają one bezpośredniego dostępu do internetu. Ruch, który z nich wychodzi, przechodzi przez bramy NAT (NAT Gateways). Każdy z obszarów (prywatny i publiczny) zawiera trzy podsieci, z których każda znajduje się w innym Data Center (AZ).
Dodatkowo, w celu utworzenia szyfrowanego dostęp do obszaru prywatnego chmury z obszaru corporate office (i tylko z tego obszaru), uruchomiliśmy w obszarze prywatnym tunel VPN site-to-site.
Inne rozwiązania, które wdrożyliśmy w tym obszarze, to dedykowane połączenie obszaru prywatnego do magazynu danych S3, dzięki czemu ruch przebiega wyznaczoną siecią z wyłączeniem internetu, oraz rozłączna adresacja IP każdej sieci VPC, celem ułatwienia realizacji połączeń VPN.
Platforma Kubernetes
Klaster Kubernetes przygotowaliśmy przy pomocy Amazon Elastic Kubernetes Service, który, poza zaletami charakterystycznymi dla platformy Kubernetes, dzięki autoskalingowi umożliwia Klientowi optymalizację kosztów utrzymania klastra, obsługę wielu środowisk składających się ze zdokeryzowanych mikroserwisów, samo-naprawianie wdrożonych aplikacji i SLA z poparciem finansowym w przypadku działania usługi na poziomie poniżej 99,95%. Co bardzo ważne dla Klienta, Amazon EKS wspiera szybkie i częste deploymenty nowych aplikacji.
Dodatkowo, w celu zapewnienia funkcjonowania klastra w oczekiwany przez NeuroSYS sposób, doinstalowaliśmy do klastra następujące komponenty:
- Ingress-controller trafik dla zapewnienia obsługi ingressów wraz z optymalizacją kosztów w postaci pojedynczego load balancera NLB dla wszystkich obsługiwanych ingressów.
- Kontroler certyfikatów cert-manager odpowiedzialny za realizację dynamicznych certyfikatów SSL, komponent ma za zadanie przejąć rolę Rancherowego lets-encrypt.
- Autoskaler cluster-autoscaler - umożliwia automatyczne skalowanie grup maszyn wraz z reschedulingiem podów
- Aktualizator wpisów DNS external-dns - automatyzuje obsługę adresów hostów zdefiniowanych w ingressach.
- Narzędzie backup-restore Velero tworzy kopie zapasowe wszystkich elementów klastra oraz ich danych
- Service mesh Linkerd - realizuje automatyczne mTLS, metryki ruchu oraz sukcesu requestów poszczególnych usług
Wszystkie powyższe narzędzia wdrożyliśmy przy użyciu i pod kontrolą narzędzia Helm, które pozwala Klientowi na utrzymywanie odpowiednich wartości konfiguracji poszczególnych narzędzi dla danego klastra w kodzie zgodnie z metodologią DevOps, kontrolę zmian i ewentualnych powrotów (roll-back) do poprzednich konfiguracji oraz łatwe utrzymanie i aktualizację pełnej konfiguracji danego narzędzia.
Bazy danych
Tworząc bazę danych braliśmy przede wszystkim pod uwagę wymagania Klienta związane ze zgodnością z obecnie przyjętymi praktykami w zakresie funkcjonowania i utrzymania oprogramowania. Dlatego też uruchomiliśmy bazy postgresowe w formie kubernetesowych podów, wykorzystujących dyski EBS poprzez PersistentVolumeClaim. Jest to forma zgodna ze wzorcem architektury mikroserwisowej, w której poszczególne mikroserwisy posiadają własną bazę danych, a zespół odpowiedzialny za mikroserwis, odpowiada również za jej utrzymanie i konfigurację. Zastosowanie takiej bazy danych pozwoliło nam również na separację na poziomie używania zasobów sprzętowych odpowiednich baz danych, należących do odpowiadających im mikroserwisów.
Szyny danych RabbitMQ
Podobnie jak w przypadku baz danych, wzięliśmy pod uwagę wymagania związane ze zgodnością z obecnymi praktykami w funkcjonowaniu i utrzymaniu oprogramowania i uruchomiliśmy RabbitMQ w formie kubernetesowych podów, wykorzystujących dyski EBS poprzez PersistentVolumeClaim. Jest to forma zgodna ze wzorcem architektury mikroserwisowej, w której dana grupa mikroserwisów posiada własną szynę danych, a dany zespół jest również odpowiedzialny za jej utrzymanie i konfigurację. Zaletą tego rozwiązania jest separacja na poziomie używania zasobów sprzętowych odpowiednich szyn danych należących do odpowiadających im grup mikroserwisów. Co ważne, koszt szyny danych w tym przypadku jest składową kosztu klastra Kubernetesa, z kolei ochrona danych dyskowych realizowana jest przez open sourcowe narzędzie Velero.
Przed migracją powyższego rozwiązania przeprowadziliśmy stress i load testy, żeby upewnić się, że zastosowane narzędzia są gotowe do planowanej migracji.
Monitoring klastrów EKS
Do monitoringu klastrów EKS oraz reszty usług AWS skonfigurowaliśmy narzędzie DataDog, które umożliwia stworzenie pojedynczego pulpitu monitorowania (single pane of glass), znacząco skracając czas reakcji na awarie i analizę incydentów. Wdrożyliśmy również DataDog agent w klastrze Kubernetes, dzięki któremu Klient może samodzielnie ocenić przydatność, funkcjonalności oraz koszty związane z używaniem DataDog.
Wdrożenie aplikacji WEB
Instalację stosu aplikacji na platformie Kubernetes wykonaliśmy przy pomocy menadżera pakietów Helm, który obecnie jest najczęściej używanym menadżerem do zarządzania aplikacjami w środowisku Kubernetes. Funkcjonalności Helm pozwalają wykorzystywać go w sposób zautomatyzowany (pipelines), umożliwiają też umieszczanie nowych wersji aplikacji, wracanie do poprzednich wersji czy usuwanie ich w ustandaryzowany sposób, korzystając z definicji aplikacji lub całego ich zestawu w formie tzw. chartów, czyli definicji wszystkich komponentów niezbędnych w klastrze do działania aplikacji.
Pozostałe rozwiązania
W charakterze magazynu obiektów (pliki statyczne, kopie, archiwalne logi, pliki stanu infrastruktury) zastosowaliśmy AWS S3. W celu szyfrowania danych w usługach AWS (dyski EBS, magazyn S3, bazy danych itp.) w integracji z natywnymi metodami uwierzytelnienia i autoryzacji, wykorzystaliśmy AWS KMS (Key Management Service). Dla przechowywania dynamicznych parametrów dostępnych dla aplikacji przy użyciu natywnych dla AWS serwisów IAM oraz KMS, w tym szyfrowanych sekretów, parametrów inicjalizacyjnych itp., zastosowaliśmy usługę Systems Manager Parameter Store, natomiast do przechowywania sekretów, ze względu na funkcjonalność automatycznej rotacji sekretów, wdrożyliśmy Secret Managera.
Podsumowanie
Dla Firmy NeuroSYS zrealizowaliśmy migrację platformy nsFlow do środowiska AWS, opartego na klastrach Kubernetes. Całe środowisko zostało stworzone w zgodzie z podejściem IaC. Ze względu na to, że po przeprowadzeniu migracji, Klient zaplanował zbudowanie zespołu zajmującego się całodobowym suportem migrowanej aplikacji, cały proces przeprowadziliśmy zgodnie z filozofią CI/CD, dzięki czemu pracownicy Klienta mogli na bieżąco wdrażać się w realizowany projekt. Ponadto, wszystkie zaimplementowane elementy kodu, uzupełniliśmy o informacje „read me”, zawierające podstawowe informacje dotyczące każdego zastosowanego rozwiązania. Dzięki temu proces wdrożenia zespołu Klienta przebiegł szybko i sprawnie.
PYTANIA? SKONTAKTUJ SIĘ Z NAMI
Zobacz również:
Migracja do Amazon Web Services aplikacji i serwisów DANONE
Wdrożenie i opieka nad infrastrukturą chmurową w AWS dla Displate
Migracja bazy danych MySQL do Amazon Aurora platformy Landingi.com
Nowa infrastruktura w AWS dla Omnipack z użyciem IaC
Migracja serwisu edukacyjnego EduNect do chmury AWS

